In this first vSphere Replication article we will have an overview of the product: how does it work? What are the components? After this overview, we will show several possible vSphere Replication designs.
Concepts
What is vSphere Replication? As the name suggests, vSphere Replication enables replication of virtual machines from a datastore to another. The destination datastore can be attached to another host, cluster, or even a datacenter. Flexibility is the strong selling point for vSphere Replication: you can protect a single virtual machine or a complete site.
Components
vSphere Replication come with two components thatcan easily be confused:
- The vSphere Replication Management Server, which is responsible for managing the replications, the permissions, the link to the vCenter Server… It stores its configuration in an integrated database (which can be externalized, which more or less ruins the concept of having an appliance, in my opinion).
- The vSphere Replication Server, which is doing the real job :). Data arrives from replicated virtual machines and the vSphere Replication Server writes it to the destination disks.
Both components are shipped together in a single virtual appliance, using the same name and IP, which increases the risk of confusion. In previous versions both roles were separated in two VMs, which made the deployment a bit more complex, but the architecture more readable. Nevertheless, once you know it, you can live with it.
How many replication servers can we have?
- There can be only one vSphere Replication Management Server for each vCenter.
- There can be up to 10 vSphere Replication Servers for each vSphere Replication Management Server (the first one being integrated to the management server, as we just said).
Let’s also mention the ESXi agent, which already exists on the hosts but must be activated and registered (this is done automatically). The ESXi agent will manage the replication at the virtual machine level, by sending data to the vSphere Replication Servers.
And finally, you will get a plugin for the vSphere Web Client, where you can manage and monitor replications. Let’s see how all these parts work together!
Under the hood
At the disk level
An administrator configures replication for VM-A, hosted on ESXi1, to a datastore of ESXi2. When the initial copy starts, all disk files (.vmdk) from the source VM are read and compared to a potential seed with same disk UUIDs on ESXi2. The delta (everything, if there is no seed) will be sent from ESXi1 to the vSphere Replication Server responsible for this replication, which will, in turn, write the replicated blocks to the selected datastore of ESXi2.
Once the initial copy is finished, the replication starts to run in synchronization mode. A SCSI filter located on ESXi1 monitors and stores all changed blocks of VM-A in a pointer file stored in the VM folder (the .psf files). At the defined interval, the list of changed blocks is combined to generate a package of blocks which will be sent to the vSphere Replication Server. Once the update package is consistent on the vSphere Replication Server, data is written to the disk at destination and a new cycle begins.
This is very similar to CBT (Changed Block Tracking), but it’s not CBT: vSphere Replication will not interfere with the backup.
Over the WAN
In our first example, ESXi1 and ESXi2 were on the same site. Let’s move ESXi2 to a remote site. What is the constraint? As we’ve seen, the vSphere Replication Server manages disk writes at the destination. Consequently, it must always be placed on the destination site. That’s not really a performance problem, as we’ve seen that vSphere Replication is quite efficient in only transmitting changed blocks, but it could require an additional new vSphere Replication Server at the destination site. This is not really an issue either, but must be planned!
In other words: you will always need a vSphere Replication Server on each destination site. This will of course affect our vSphere Replication designs.
Bandwidth management (lack of…)
vSphere Replication comes without any bandwidth regulation mechanism. Restricting the replication to specific hours isn’t possible either. This could cause problems on smaller WAN links. If you have tools to identify and prioritize network traffic, you can manage the vSphere Replication traffic with the following ports:
- 31031: initial replication
- 44046: on-going replication
Without QoS, you could control the bandwidth usage of vSphere Replication by configuring a dedicated virtual port group and enable ingress traffic shaping. However, this requires a dvSwitch (available in vSphere Enterprise Plus).
Possible architectures
More constraints!
Until now we have focused on how the replication works. What about the recovery? Well, there is a big constraint: to restore a replicated virtual machine, you need access to the vCenter Server and the attached vSphere Replication Management Server!
In other words, in a cross-site replication scenario, you would need the vSphere Replication Management Server and vCenter Server on the destination site, which is generally not acceptable if the destination site is a secondary site, or a disaster-recovery site.
What are the possibilities? Well, there aren’t that many possibilities! If you plan to use vSphere Replication as a site disaster recovery tool, you’ll need a second vCenter and Replication Management Server at the destination site.
Now that we have a clear overview of the design constraints, we can propose some possible designs for vSphere Replication, based on several typical use cases.
Protected virtual machines on a single site
Use case: we wish to protect one or more applications, or at maximum a complete production cluster. We plan to recover these applications on the same site, on dedicated spare hardware.
Constraints: we need dedicated hardware for the recovery obviously, but we also need dedicated hardware, separated from production, to host the management tools (vCenter Server, vSphere Replication appliance, but probably also a domain controller and other infrastructure tools) if we want to protect a complete production cluster.
Design proposal: we are going to combine the dedicated hardware planned for the recovery with the hardware needed for the management platform. This will avoid having too much underused hardware and allows us to fully dedicate the production cluster to host production machines. Both environments could be in different rooms as long as a reliable network is ensured.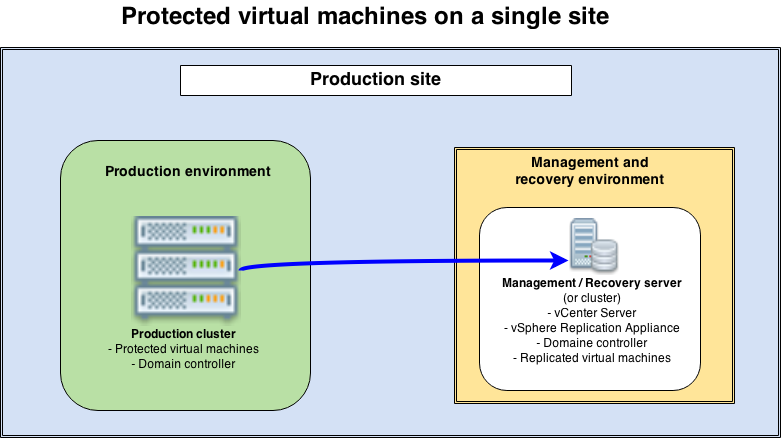 The main benefit of this strategy is that you don’t have sleeping hardware, as the disaster recovery environment is used to host the management tools (but of course, it must be sized appropriately to recover the virtual machines when a disaster happens!).
The main benefit of this strategy is that you don’t have sleeping hardware, as the disaster recovery environment is used to host the management tools (but of course, it must be sized appropriately to recover the virtual machines when a disaster happens!).
Protected production site(s) with a dedicated recovery site
Use case: typically, this is the case of a company who rents servers (or rack space with its own servers) at a hosting provider. This environment will receive incoming replications from one or more production sites. Of course, the recovery environment must host some “hot” virtual machines, at least the disaster recovery vCenter and vSphere Replication Appliance, probably a domain controller too.
Constraints: good network connectivity between sites is a must. Also, the servers in the disaster recovery environment must be sized large enough to support the recovery of the biggest production site.
Design proposal: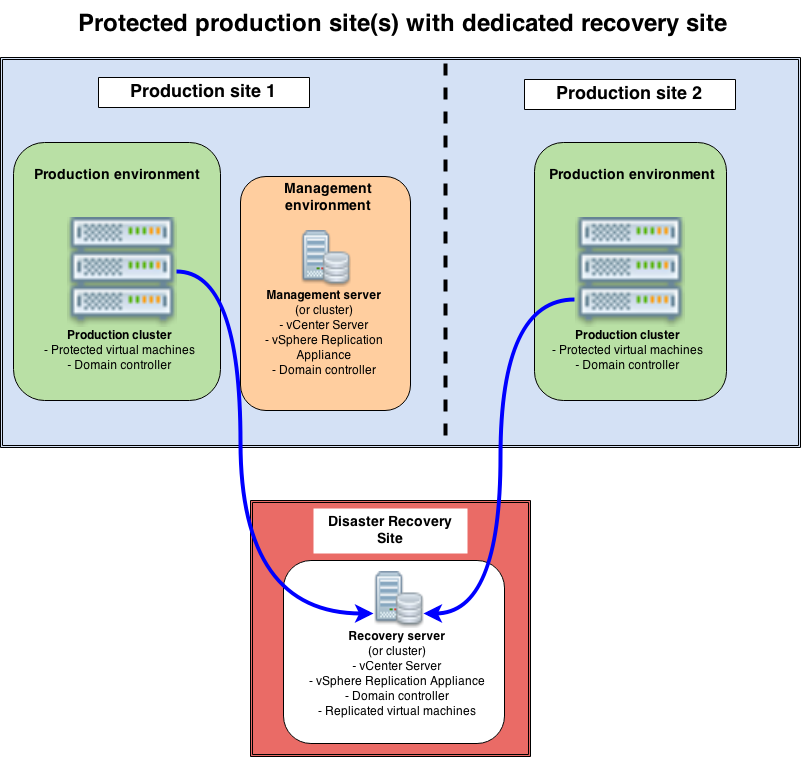 Two production sites are shown here, but of course there could just be a single one. The management environment (in orange) is separated for better readability, but could be integrated in the production cluster in smaller environments. In the multi-site scenario, only one management environment (still in orange) is required (you don’t need a new vCenter + Replication Appliance on each production site).
Two production sites are shown here, but of course there could just be a single one. The management environment (in orange) is separated for better readability, but could be integrated in the production cluster in smaller environments. In the multi-site scenario, only one management environment (still in orange) is required (you don’t need a new vCenter + Replication Appliance on each production site).
Bidirectional site protection
Use case : a company has two production sites and each site is going to protect the other site. While the previous design was active/passive, this one will be active/active. It could be scaled to more sites.
Constraints : each site will have its own management environment (vSphere Replication Management Server, vCenter Server…). Therefore, if you wish to keep a centralized administration for the daily work, a Linked Mode installation of vCenter is required. Both production environments must be sized to host the replicated virtual machines if necessary.
Design proposal: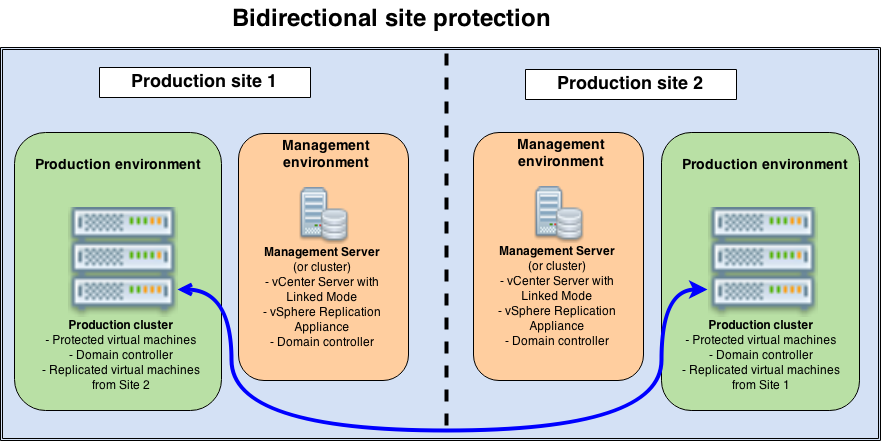 As in the previous design, the management environments are show separated from the cluster (which makes sense for bigger environments), but they could be integrated as well.
As in the previous design, the management environments are show separated from the cluster (which makes sense for bigger environments), but they could be integrated as well.
Conclusion
We have seen how vSphere Replication works and studied three typical designs. But there are many other options, as the product is flexible and will adapt to your needs.
In the next vSphere Replication articles, we will deploy a complete environment in a scenario similar to our second case, with a dedicated server in a remote site that will be used to host replicas. However, the procedure would be almost the same in a bidirectional scenario; you would just need to configure replications the other way too!